TCP/IP로 보는 네트워크
TCP/IP 기초부터 실전까지: 네트워크 통신의 모든 것
인터넷은 매일 사용하지만, 실제로 데이터가 어떤 방식으로 이동하는지 정확히 이해하고 있는 사람은 많지 않습니다. 웹사이트 하나를 열고 메시지 하나를 보내는 단순한 행동 뒤에도 복잡한 네트워크 통신 과정이 숨어 있습니다. 개발자나 서버 엔지니어가 되면 결국 TCP/IP를 반드시 이해해야 한다는 말을 자주 듣게 되는 이유도 여기에 있습니다.
특히 클라우드와 DevOps 환경이 일반화되면서 네트워크 지식은 특정 인프라 엔지니어만의 영역이 아니게 됐습니다. 애플리케이션 장애 분석부터 보안 설정, 서버 성능 문제까지 대부분 TCP/IP 구조와 연결되기 때문입니다.
TCP/IP를 이해하기 전에 네트워크 통신부터 알아야 하는 이유
인터넷은 수많은 장비가 데이터를 계속 주고받는 거대한 통신망에 가깝습니다. 우리가 브라우저 주소창에 URL을 입력하면 요청 데이터가 여러 네트워크 장비를 거쳐 목적지 서버로 이동하고, 다시 응답 데이터를 받아오는 과정이 반복됩니다.
이때 데이터는 한 번에 통째로 이동하지 않습니다. 작은 단위의 패킷으로 잘려 이동합니다. 각 패킷에는 출발지와 목적지 주소, 순서 정보 등이 함께 포함됩니다.
네트워크 통신 구조를 이해하지 못하면 서버 장애 상황에서도 원인을 찾기 어렵습니다. 예를 들어 웹사이트 접속이 느릴 때 단순히 서버 성능 문제라고 생각하기 쉽지만, 실제 원인은 DNS 지연이나 TCP 연결 문제인 경우도 많습니다.
실무에서는 “서버는 정상인데 왜 연결이 안 되지?” 같은 상황이 자주 발생합니다. 이때 TCP/IP 흐름을 이해하고 있으면 어느 단계에서 문제가 생겼는지 빠르게 추적할 수 있습니다.
Cloudflare 역시 TCP/IP를 인터넷 통신의 기본 언어라고 설명합니다. 인터넷에 연결된 대부분의 장비가 TCP/IP 프로토콜을 기반으로 데이터를 교환하기 때문입니다.
STEP 1. TCP/IP는 정확히 무엇을 의미할까
TCP/IP는 하나의 기술이라기보다 여러 네트워크 통신 규칙을 묶은 구조에 가깝습니다.
여기서 IP는 데이터를 목적지까지 전달하는 역할을 담당합니다. 쉽게 말하면 “어디로 보내야 하는가”를 결정하는 주소 체계에 가깝습니다.
반면 TCP는 데이터가 제대로 도착했는지 확인하는 역할을 맡습니다. 데이터 순서가 틀어지지 않았는지, 중간에 손실된 패킷은 없는지 검사하면서 안정적인 통신을 유지합니다.
이 둘이 함께 동작하기 때문에 인터넷 통신이 안정적으로 유지될 수 있습니다. IP만 존재한다면 데이터는 목적지 방향으로 이동할 수 있지만, 중간 손실이나 순서 문제를 해결하기 어렵습니다.
여기서 자주 등장하는 개념이 프로토콜입니다. 프로토콜은 장비끼리 데이터를 주고받기 위한 약속이라고 이해하면 쉽습니다. 서로 같은 규칙을 사용해야 통신이 가능하기 때문입니다.
예를 들어 HTTP는 웹 통신 규칙이고, SMTP는 이메일 전송 규칙입니다. TCP/IP는 이런 다양한 프로토콜이 동작하는 기반 구조 역할을 합니다.
처음 네트워크를 공부할 때 가장 어려운 부분도 바로 이런 계층 구조와 프로토콜 개념입니다. 하지만 브라우저에서 웹사이트 하나가 열리는 흐름을 따라가다 보면 훨씬 이해하기 쉬워집니다.
STEP 2. TCP/IP 4계층 구조를 흐름으로 이해하기
TCP/IP는 일반적으로 4계층 구조로 설명됩니다. 애플리케이션 계층, 전송 계층, 인터넷 계층, 네트워크 인터페이스 계층으로 구성됩니다.
애플리케이션 계층은 사용자가 직접 사용하는 서비스와 가장 가까운 영역입니다. HTTP, HTTPS, DNS 같은 프로토콜이 여기에 포함됩니다.
전송 계층에서는 TCP와 UDP가 동작합니다. 데이터 전달 방식과 안정성을 관리하는 핵심 계층입니다.
인터넷 계층에서는 IP 주소 기반으로 패킷 경로를 결정합니다. 쉽게 말하면 어떤 네트워크를 통해 목적지까지 이동할지 판단하는 역할입니다.
마지막 네트워크 인터페이스 계층은 실제 물리 장비와 연결되는 영역입니다. 랜카드나 스위치 같은 장비와 직접 연결됩니다.
실제 네트워크 통신에서는 데이터가 이 계층들을 차례대로 지나가며 이동합니다. 예를 들어 사용자가 브라우저에서 웹사이트 주소를 입력하면 먼저 DNS 조회가 이루어지고, 이후 TCP 연결을 생성한 뒤 HTTP 요청 데이터가 서버로 전달됩니다.
반대편 서버에서는 다시 계층을 올라가며 요청 데이터를 해석하고 응답을 반환합니다. 이 과정이 매우 빠르게 반복되기 때문에 사용자는 단순히 웹페이지가 열리는 것처럼 느끼게 됩니다.
| TCP/IP 계층 | 주요 역할 | 대표 프로토콜 |
|---|---|---|
| 애플리케이션 계층 | 사용자 서비스 처리 | HTTP, HTTPS, DNS |
| 전송 계층 | 데이터 전달 관리 | TCP, UDP |
| 인터넷 계층 | IP 기반 라우팅 | IP, ICMP |
| 네트워크 인터페이스 계층 | 물리 네트워크 연결 | Ethernet, Wi-Fi |
이 흐름을 이해하면 네트워크 문제를 훨씬 체계적으로 분석할 수 있습니다. 예를 들어 DNS 문제인지, TCP 연결 문제인지, 라우팅 문제인지 구분하는 데 도움이 됩니다.
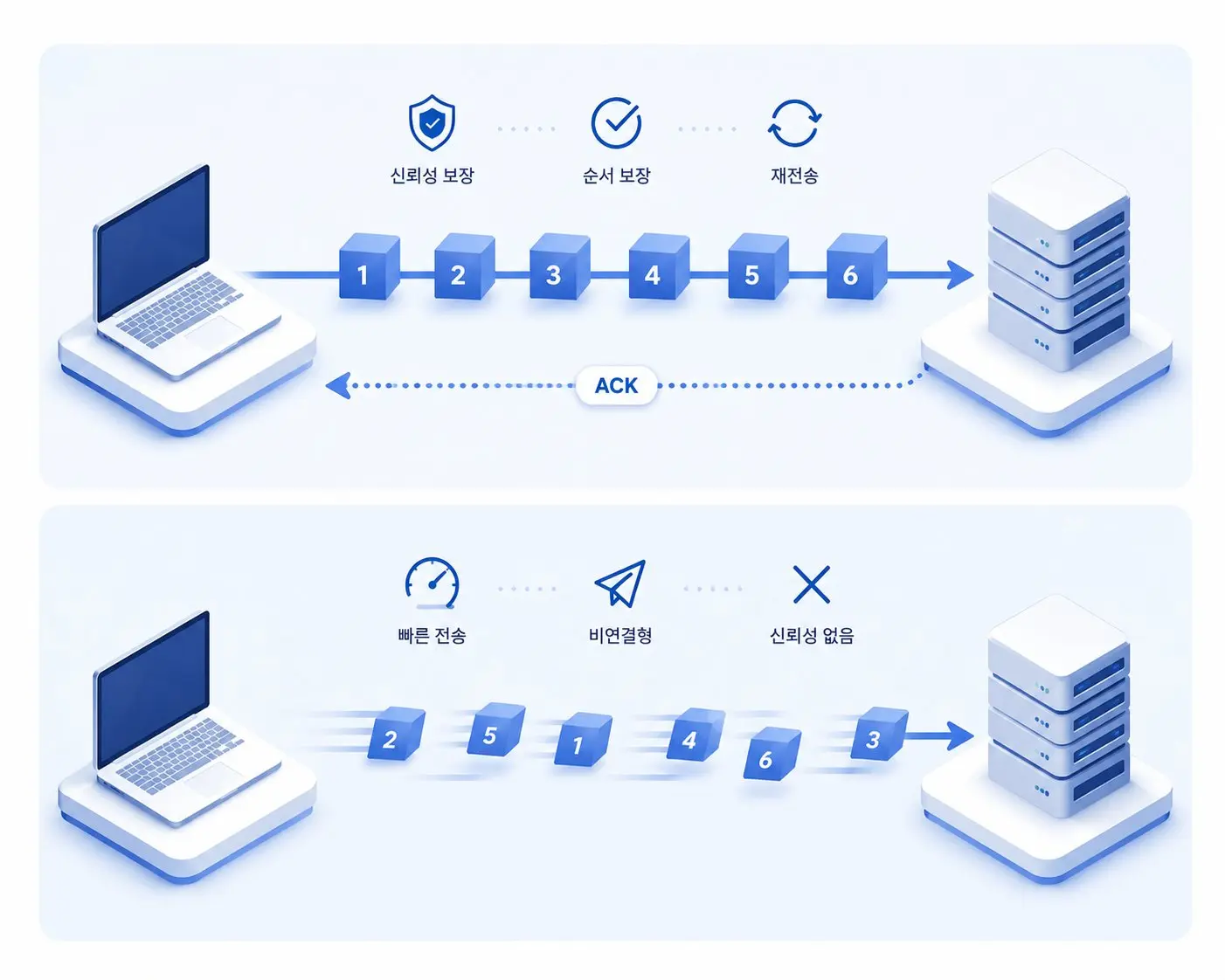
STEP 3. TCP는 왜 신뢰성 있는 통신이라고 불릴까
TCP는 연결 지향형 프로토콜입니다. 데이터를 보내기 전에 먼저 상대방과 연결을 설정합니다.
대표적인 과정이 3-way Handshake입니다. 먼저 클라이언트가 연결 요청을 보내고, 서버가 응답한 뒤 다시 클라이언트가 확인 메시지를 보내면서 연결이 성립됩니다.
이 과정을 거치기 때문에 TCP는 상대방이 실제로 연결 가능한 상태인지 먼저 확인할 수 있습니다.
또한 TCP는 데이터 순서를 보장합니다. 만약 중간에 패킷이 유실되면 재전송을 요청합니다. 이런 구조 덕분에 파일 다운로드나 웹 페이지 로딩처럼 정확성이 중요한 서비스에서 TCP가 주로 사용됩니다.
특히 금융 서비스나 결제 시스템에서는 데이터 손실이 매우 치명적이기 때문에 대부분 TCP 기반 통신을 사용합니다. 웹 브라우저 역시 기본적으로 TCP 연결 위에서 동작합니다.
흐름 제어 기능도 중요한 특징입니다. 상대방이 처리 가능한 속도보다 지나치게 많은 데이터를 보내지 않도록 조절하는 역할입니다.
실무에서는 TCP 연결 상태를 분석하는 일이 매우 많습니다. 특히 서버 응답 지연이나 연결 실패 문제를 확인할 때 SYN, ACK 같은 TCP 상태 값을 자주 확인하게 됩니다.
STEP 4. UDP는 왜 빠른 통신에 사용될까
UDP는 연결 설정 과정 없이 빠르게 데이터를 전송하기 때문에 실시간 서비스에서 자주 사용됩니다.
UDP는 TCP보다 훨씬 단순한 구조를 사용합니다. 연결 설정 과정 없이 바로 데이터를 전송합니다.
가장 큰 특징은 속도입니다. 연결 확인이나 재전송 과정이 없기 때문에 지연 시간이 매우 짧습니다.
대신 데이터 손실 가능성은 존재합니다. 패킷이 중간에 사라져도 UDP는 다시 요청하지 않습니다.
이 때문에 실시간성이 중요한 서비스에서 UDP가 많이 사용됩니다. 온라인 게임, 음성 통화, 실시간 스트리밍 서비스가 대표적입니다.
예를 들어 온라인 게임에서는 패킷이 조금 손실되더라도 즉시 다음 데이터를 받아오는 것이 더 중요합니다. 반대로 재전송 때문에 화면이 멈추거나 입력 반응이 늦어지는 상황은 사용자 경험에 훨씬 큰 영향을 줄 수 있습니다.
영상 통화 역시 비슷합니다. 화면이 잠깐 깨지는 것보다 통화 자체가 끊기지 않는 것이 더 중요하기 때문에 UDP 기반 구조가 자주 사용됩니다.
- TCP: 안정성과 정확성 중심
- UDP: 속도와 실시간성 중심
- TCP: 재전송 및 연결 확인 수행
- UDP: 빠른 전송 우선
- TCP 사용 예시: 웹, 결제, 파일 다운로드
- UDP 사용 예시: 게임, 스트리밍, 음성 통화
최근에는 QUIC 같은 최신 프로토콜도 UDP 기반 위에서 동작하면서 TCP의 일부 안정성 기능을 결합하는 방향으로 발전하고 있습니다.
STEP 5. IP 주소와 포트 번호는 어떻게 동작할까
IP 주소는 네트워크상에서 장비를 구분하기 위한 주소입니다. 인터넷에 연결된 모든 장비는 IP 주소를 사용해 서로를 식별합니다.
공인 IP는 인터넷에서 직접 접근 가능한 주소입니다. 반면 사설 IP는 내부 네트워크에서만 사용하는 주소입니다.
집이나 회사에서 공유기를 사용하는 경우 대부분 내부 장비는 사설 IP를 사용하고, 외부 인터넷 연결은 공유기의 공인 IP를 통해 이루어집니다.
포트 번호는 하나의 장비 안에서 어떤 프로그램과 통신할지를 구분하는 역할을 합니다.
예를 들어 웹 서버는 일반적으로 80번이나 443번 포트를 사용합니다. 데이터베이스 서버는 3306이나 5432 같은 포트를 사용하는 경우가 많습니다.
같은 서버 안에서도 여러 애플리케이션이 동시에 동작할 수 있는 이유가 바로 포트 번호 때문입니다.
실무에서는 방화벽 설정이나 서버 보안 작업을 할 때 포트 개념이 매우 중요합니다. 실제 장애 상황에서도 특정 포트가 막혀 통신이 실패하는 경우가 자주 발생합니다.
STEP 6. 실무에서 TCP/IP 지식이 중요한 이유
TCP/IP는 단순한 이론 과목이 아니라 실제 시스템 운영과 직접 연결되는 핵심 지식입니다.
예를 들어 서버 응답 속도가 느려졌을 때 원인이 애플리케이션인지, DNS 문제인지, 네트워크 지연인지 구분하려면 TCP/IP 흐름을 이해하고 있어야 합니다.
특히 클라우드 환경에서는 네트워크 구조가 더욱 복잡해집니다. 로드밸런서, NAT 게이트웨이, 보안 그룹, 프록시 서버 같은 요소들이 모두 TCP/IP 기반 위에서 동작합니다.
보안 분야에서도 TCP/IP는 기본입니다. DDoS 공격 분석, 포트 스캔 탐지, 패킷 필터링 같은 개념 역시 TCP/IP 이해 없이는 접근하기 어렵습니다.
실제로 많은 개발자가 애플리케이션 코드에는 익숙하지만 네트워크 계층 문제에서는 원인을 찾지 못하는 경우가 많습니다. 하지만 TCP/IP 구조를 이해하면 로그 분석이나 장애 대응 속도가 훨씬 빨라집니다.
예를 들어 서버 자체는 정상인데 특정 포트만 차단되어 서비스 접속이 실패하는 사례도 매우 흔합니다. 네트워크 흐름을 이해하고 있으면 이런 문제를 훨씬 빠르게 발견할 수 있습니다.
결국 TCP/IP는 인터넷을 움직이는 핵심 구조라고 볼 수 있습니다. 클라우드, 보안, 서버 운영, DevOps까지 대부분의 IT 인프라 기술이 이 기반 위에서 동작하기 때문입니다.